Module list
System Overview
Fig. 2 shows the system overview of DODDLE-OWL. DODDLE-OWL has the following six main modules: Ontology Selection Module, Input Module, Construction Module, Refinement Module, Visualization Module, and Translation Module.
Hierarchy Construction Module and Hierarchy Refinement Module were included in DODDLE-I [Yamaguchi99] to support the user construct taxonomic relationships. Relationship Construction Module and Relationship Refinement Module, both added on to DODDLE-II [Kurematsu04] , support the construction of taxonomic and other rela- tionships. Ontology Selection Module, Input Module, Visualization Module, and Translation Module were additionally integrated in DODDLE-OWL to make possible an interactive domain ontology development environment.
Here, we assume that there are one or more domain specific documents, and we also assume that the users can select important terms that are needed to construct a domain ontology.
First, as input of DODDLE-OWL, the users select several concepts in Input Module. In Construction Module, DODDLE-OWL generates the basis of an ontology, an initial concept hierarchy and set of concept pairs, by referring to reference ontologies and documents. In Refinement Module, the initial ontology generated by Construction Module is refined by the users through interactive support by DODDLE-OWL. The ontology constructed by DODDLE-OWL can be exported with the representation of OWL. Finally, Visualization Module (MR3 [Morita06] ) is connected with DODDLE-OWL and works with an graphical editor.
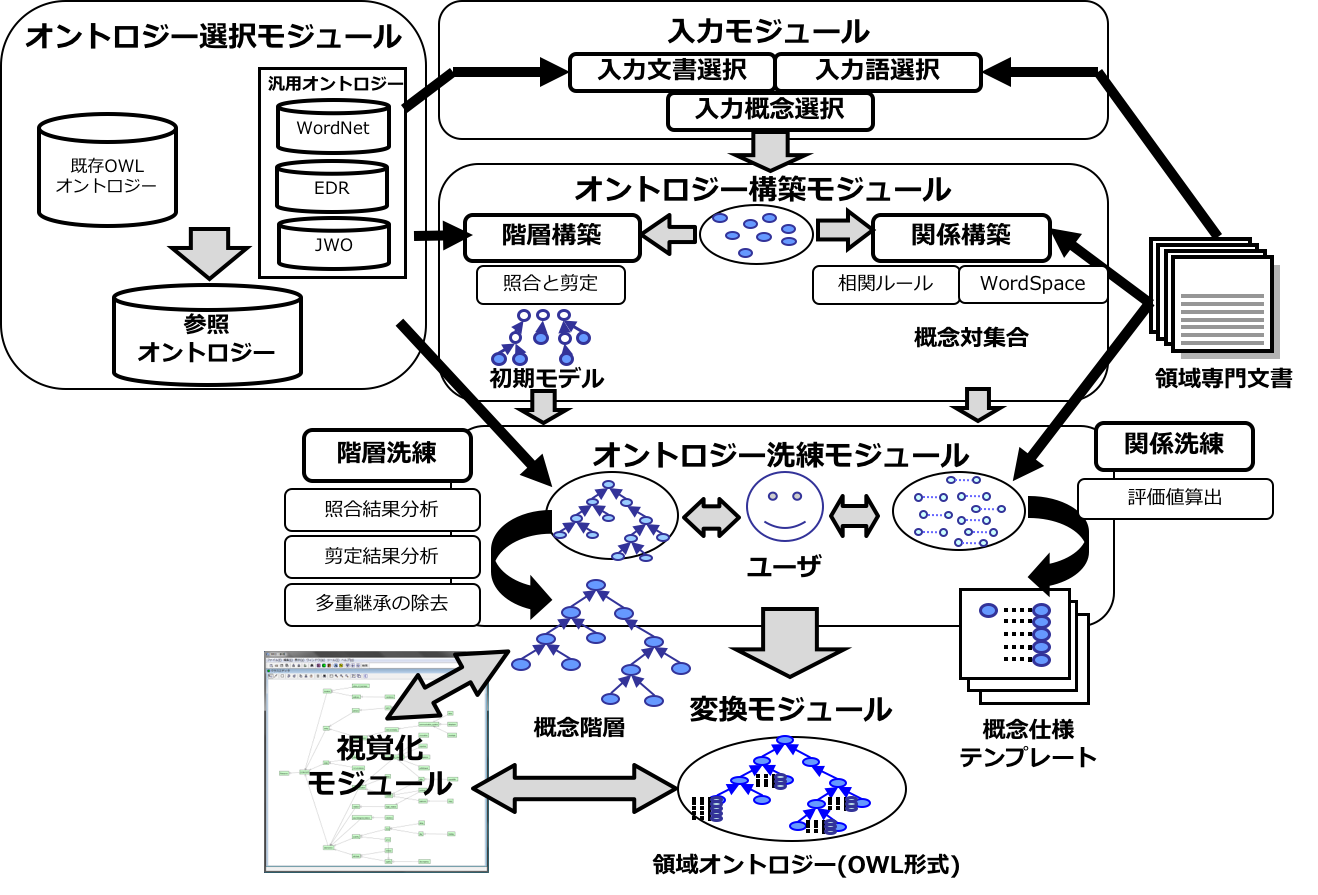
Fig. 2 System overview of DODDLE-OWL
Ontology Selection Module
In the ontology selection module, the user selects a reference ontology. A reference ontology serves as the foundation for building a domain ontology and is referenced by each module within DODDLE-OWL. DODDLE-OWL supports several reference ontologies, including WordNet [Miller95], Japanese WordNet [Isahara08], EDR [Yokoi95], and the Japanese Wikipedia Ontology (JWO) [Tamagawa10]. Furthermore, existing ontologies described in OWL (Web Ontology Language) format can also be utilized as reference ontologies.
General ontologies such as WordNet and EDR provide broad and exhaustive definitions. Consequently, when applying them to domain ontology construction, they require refinement into a domain-specific structure, involving tasks such as modifying hierarchical relationships and removing irrelevant concepts. This process imposes a significant burden on the user. On the other hand, if a domain ontology related to the target domain already exists, reusing it can reduce the cost of refinement compared to using a general ontology. Since ontologies constructed via DODDLE-OWL are exported in OWL format, they can also be reused as reference ontologies. Therefore, in DODDLE-OWL, general ontologies are utilized when no existing domain ontology is available or when existing ones do not sufficiently cover the target domain. Conversely, if a relevant domain ontology exists, using it as a reference ontology enables more efficient support for constructing the target domain ontology.
To facilitate the reuse of existing ontologies available on the Web, the ontology selection module is equipped with a domain ontology acquisition function that utilizes ontology search engines. The following sections provide a brief overview of general ontologies, followed by a description of the methodology for acquiring existing domain ontologies using ontology search engines.
Note
Since the Swoogle ontology search engine discontinued its service on May 1, 2010, the domain ontology acquisition function utilizing Swoogle is currently unavailable.
General Ontologies
DODDLE-OWL supports several general ontologies, including WordNet, Japanese WordNet, the EDR Electronic Dictionary (comprising both general and specialized dictionaries), and the Japanese Wikipedia Ontology (JWO). The following sections provide an overview of each of these ontologies.
WordNet
WordNet [Miller95] is an English thesaurus (general ontology) developed at Princeton University. It is composed of separate dictionaries for nouns, verbs, adjectives, and adverbs, as well as an index file (index of headwords), collectively containing approximately 100,000 lexical items.
The index of headwords consists of the headword itself, a Concept ID (Synset offset) serving as semantic information, lexicographer information, and part-of-speech (POS) tags. The Concept ID functions as a link connecting the headword index to the respective syntactic category dictionaries.
The noun and verb dictionaries consist of Concept IDs, lexicographer information, and a list of corresponding headwords. These concepts are organized into a hierarchical structure (taxonomy). Furthermore, specific Concept IDs are associated with relations such as Antonyms, as well as meronymous relations including part-of, member-of, and substance-of. While the adjective and adverb dictionaries also contain Concept IDs, lexicographer information, and corresponding headword lists, they do not possess a hierarchical structure.
Japanese WordNet
Japanese WordNet [Isahara08] is the Japanese counterpart of WordNet.
EDR Electric Dictionary
The EDR Electronic Dictionary [Yokoi95] is a general ontology provided by the National Institute of Information and Communications Technology (NICT). The EDR Electronic Dictionary is a comprehensive resource consisting of the following components: Japanese Word Dictionary, English Word Dictionary, Headconcept Dictionary, Japanese-English Bilingual Dictionary, English-Japanese Bilingual Dictionary, Japanese Co-occurrence Dictionary, English Co-occurrence Dictionary, Japanese Corpus, English Corpus, and the Technical Terminology Dictionary (Information Processing). Among these resources, DODDLE-OWL specifically utilizes the Japanese Word Dictionary, English Word Dictionary, Headconcept Dictionary, and the Technical Terminology Dictionary (Information Processing).
Japanese Wikipedia Ontology
Japanese Wikipedia Ontology (JWO) [Tamagawa10] is a large-scale Japanese general ontology constructed from various resources within the Japanese version of Wikipedia, such as category trees, list-style articles, redirect links, Infoboxes, and Infobox templates.
Aquiring existing domain ontologies using an ontology search engine
To reuse existing domain ontologies, it is necessary to search the Web for ontologies relevant to the target domain. OntoSelect [Buitelaar04] and Swoogle [Ding05] are well-known examples of ontology search engines. OntoSelect is a system designed to support the searching, selection, and browsing of ontologies on the Web. As of 2007, Swoogle had indexed over 10,000 ontologies, enabling searches at the class and property levels, as well as the discovery of inverse link relationships that are not explicitly defined within the ontologies.
While these existing search engines can be used to find domain-related ontologies, they present several challenges from the perspective of domain ontology construction. Although they support searches for individual classes or properties, they do not sufficiently support the retrieval of entire ontologies encompassing multiple relevant classes and properties, nor do they adequately filter for ontologies with high relevance to a specific target domain. Swoogle introduces OntoRank, an ontology-specific ranking method similar to Google’s PageRank [Page98], and TermRank, which targets classes and properties. In both OntoRank and TermRank, classes and properties referenced by a large number of Semantic Web documents receive higher evaluations. However, for the purpose of domain ontology construction, an ontology that is frequently referenced across the Semantic Web is not necessarily the most suitable for a specific target domain. Therefore, a mechanism is required to appropriately search for existing ontologies relevant to the user’s target domain. Furthermore, it is rare that an existing ontology can be reused without modification. Consequently, it is desirable for a domain ontology construction support environment to be seamlessly integrated with an ontology search engine.
Swoogle provides 19 types of RESTful Web services (Swoogle Web Services) for ontology retrieval. Since reusing existing ontologies within DODDLE-OWL necessitates automated searching via software, Swoogle—which provides these Web services—is utilized for the acquisition of existing domain ontologies. The ontology selection module performs the acquisition and ranking of existing ontologies using Swoogle, according to the procedure shown in Fig. 3.
Acquisition of Input Concepts: Acquire classes and properties (input concepts) that contain the input terms as their URI local names or as values of the rdfs:label property.
Property Acquisition based on Input Classes: Acquire properties that have the classes obtained in Step 1 defined as their domain (rdfs:domain) or range (rdfs:range).
Class Acquisition based on Property Context: Acquire classes that correspond to the domain and range of the properties obtained in Steps 1 and 2.
Acquisition of Defining Ontologies: Acquire the ontologies that define the classes and properties obtained in Steps 1 through 3.
Element Extraction: Extract specific elements from the ontologies acquired in Step 4.
Property Filtering: Among the properties defined in the ontologies acquired in Step 4, remove those whose domain and range are neither the input concepts nor superconcepts of the input concepts.
Ranking: Rank the existing ontologies acquired in Step 4.
Details regarding Step 5 are provided in the section Extracting ontological elements from existing ontologies, and details regarding Step 7 are provided in Ranking existing ontologies.
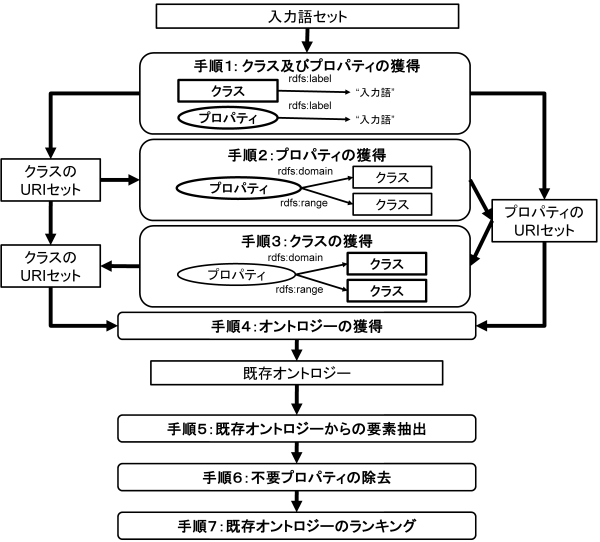
Fig. 3 The procedure flow for acquiring and ranking existing ontologies for a target domain using Swoogle
Extracting ontological elements from existing ontologies
In order to utilize OWL ontologies as reference ontologies for domain ontology construction support, it is necessary to extract elements that can be leveraged for this purpose. DODDLE-OWL facilitates the definition of taxonomic (hierarchical) relations and non-taxonomic relations within a domain ontology. The essential elements of an OWL ontology required for defining these relations include concepts (classes and properties), lexical labels (headings), concept definitions (descriptions), hierarchical relations, and other semantic relations.
The extraction of concepts is indispensable for domain ontology construction. Lexical labels are required for input concept selection, where input terms are mapped to their corresponding concepts. Concept definitions provide the necessary context for the user to make an informed decision when multiple candidate concepts exist for a single input term. Hierarchical relations are essential for building class hierarchies and property hierarchies. To define other semantic relations, it is necessary to extract the domain (rdfs:domain) and range (rdfs:range) of the properties. Ontology description languages such as RDFS, DAML, and OWL provide the fundamental classes and properties required to define these elements.
Swoogle enables ontology retrieval based on the fundamental classes and properties provided by RDFS, DAML, and OWL. For instance, Swoogle defines a class as any resource \(X\) that satisfies the following statement \((X, Y, Z)\):
\(X\) is not an anonymous resource (blank node).
\(Y\) is the
rdf:typeproperty.\(Z\) is one of the following classes:
\[\begin{split}Z \in \{ \text{rdfs:Class, owl:Class, owl:Restriction, owl:DataRange, } \\ \text{daml:Class, daml:Datatype, daml:Restriction} \}\end{split}\]
If the goal were only to extract classes and properties within the scope handled by Swoogle, following Swoogle’s definitions would suffice. However, there are general ontologies and thesauri defined in other formats. [Koide06] discusses the conversion of WordNet and EDR into OWL, noting that their structures differ from the classes and properties defined in Swoogle. Fig. 4 illustrates the different representation methods for “lexical labels” in the OWL base vocabulary, SKOS (Simple Knowledge Organisation System) [Miles05], and WordNet RDF/OWL.
[Nakayama06] proposes Wikipedia mining as a method for applying Web mining to Wikipedia and has constructed a thesaurus dictionary (wikipedia-lab). SKOS is employed as the vocabulary to represent this Wikipedia thesaurus. In SKOS, vocabularies such as skos:Concept for representing concepts and skos:broader for representing broader (superordinate) concepts are defined, which differ from the OWL base vocabulary. Table 1 lists the classes and properties used to identify ontology elements in the OWL base vocabulary, SKOS, and WordNet RDF/OWL.
To extract ontology elements from diverse formats, DODDLE-OWL utilizes five types of templates: Class Extraction, Property Extraction, Label/Description Extraction, Hierarchical Relation Extraction, and Other Relation Extraction. These templates are described using the RDF query language SPARQL [hommeaux08] and are mapped to the respective OWL ontologies.
Fig. 4 shows the difference of the labels of concepts among OWL basic vocabulary, SKOS, and the WordNet RDF/OWL scheme. In Fig. 4, we regard a synset in WordNet as a concept.
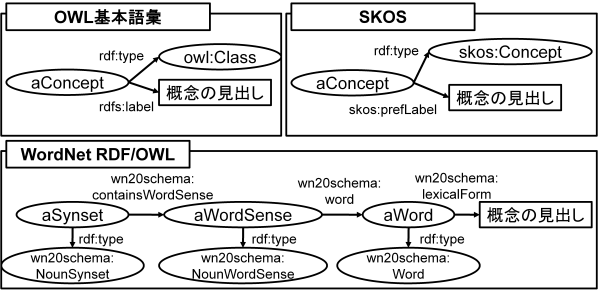
Fig. 4 Difference of the labels of concepts among OWL Basic Vocabulary, SKOS, and the WordNet RDF/OWL scheme
Ontological Elements |
Classes and properties for identifying ontology elements |
|---|---|
Concept |
rdfs:Class, owl:Class, rdf:Property, owl:ObjectProperty, etc.skos:Conceptwn20schema:WordSense, wn20schema:NounWordSense, etc. |
Concept Labels |
rdfs:labelskos:prefLabel, skos:altLabel, skos:hiddenLabelwn20schema:lexicalForm |
Concept Descriptions |
rdfs:commentskos:definitionwn20schema:gloss |
Hierarchical Relations |
rdfs:subClassOf, rdfs:subPropertyOfskos:broader, skos:narrowerwn20schema:hypernymOf, wn20schema:hyponymOf |
Other Relations |
rdfs:domain, rdfs:rangeskos:relatedwn20schema:antonymOf, wn20schema:partMeronymOf, etc. |
Ranking existing ontologies
Currently, DODDLE-OWL employs four metrics for ranking ontologies: OntoRank, TermRank, the coverage ratio of input concepts within the ontology, and the number of non-taxonomic relations pertaining to those input concepts. OntoRank and TermRank are metrics proposed in [Ding05] specifically designed for ranking ontologies, classes, and properties.
In this study, we hypothesize that an ontology containing a higher number of input concepts is more likely to be relevant to the target domain. Furthermore, we assume that an ontology defining a greater number of non-taxonomic relations related to these input concepts also possesses higher domain relevance. For ontologies with a similar coverage ratio of input concepts, OntoRank serves as a reference, allowing users to prioritize and reuse ontologies that are frequently referenced across various Semantic Web documents.
In cases where multiple candidates for an input concept exist due to lexical ambiguity, users can refer to TermRank to select and reuse input concepts that are more widely referenced by other ontologies.
Issues for reusing ontologies
To support hierarchy construction, DODDLE-OWL extracts paths relevant to the input concepts from the reference ontologies, integrates them, and prunes unnecessary concepts. When integrating paths derived from heterogeneous ontologies scattered across the Web, simple merging is difficult due to discrepancies in the structures of their superconcept hierarchies. Therefore, it is necessary to identify similar concepts through ontology alignment.
Currently, hierarchy construction support utilizing ontology alignment has not yet been implemented. Regarding ontology alignment, various tools have been made public, and competitive evaluations (contests) are actively being held. The integration of such ontology alignment tools with DODDLE-OWL remains a subject for future work.
Input Modules
The input module receives a collection of domain-specific documents as input, references the reference ontology, and outputs a set of input concepts. This module is composed of three sub-modules: the input document selection module, the input term selection module, and the input concept selection module. The system flow of the input module is illustrated in Fig. 5. The following sections provide a detailed description of each module.
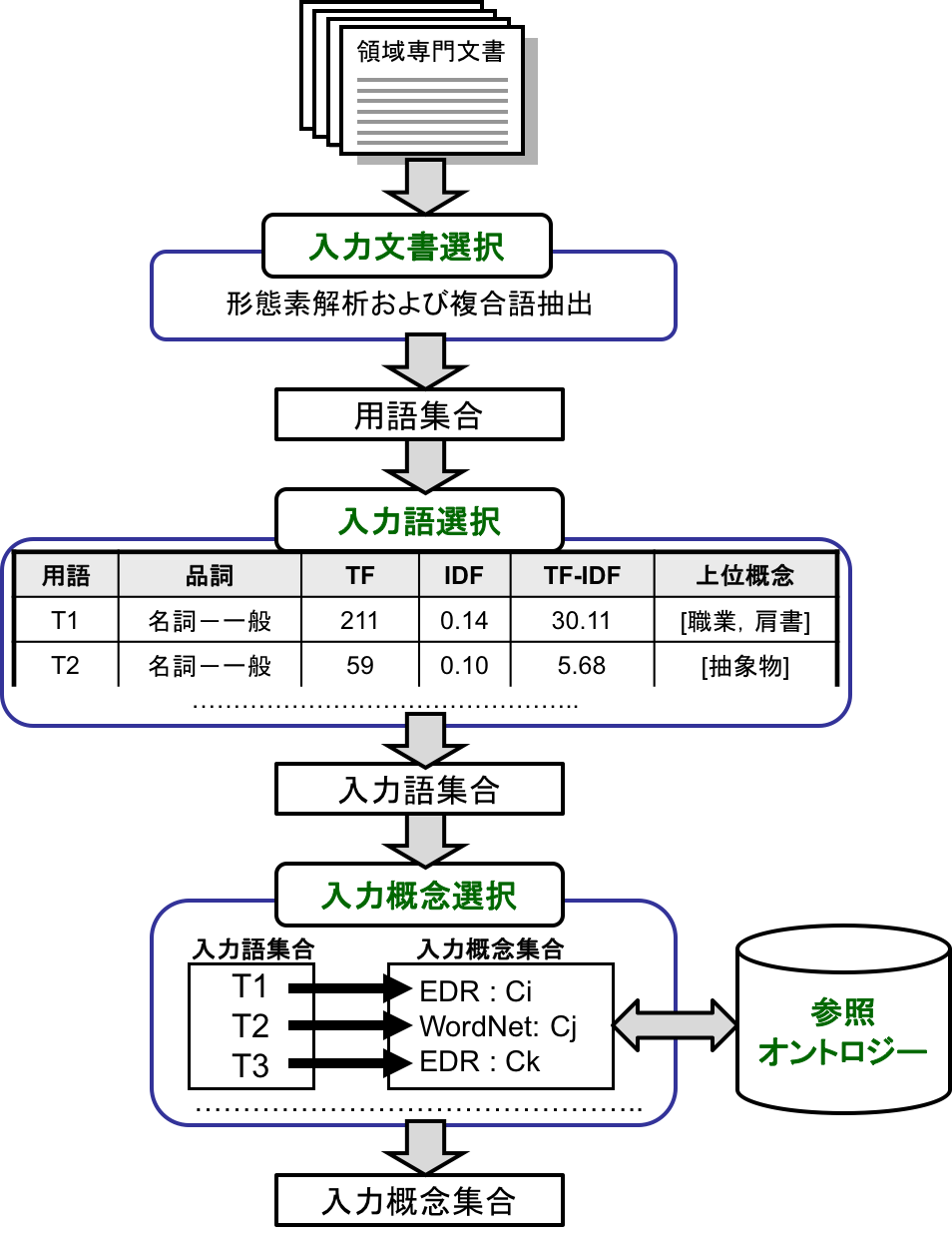
Fig. 5 System flow of Input Module
Input Document Selection Module
In the input document selection module, the user selects a collection of technical documents related to the target domain—written in either English or Japanese—as the input document set. From this set, the module extracts a term set, which serves as candidates for input terms (words of high importance to the domain). Utilizing a morphological analyzer, the module can extract words from the technical documents that correspond to user-specified parts of speech (POS). The specifiable POS categories include nouns, verbs, and other grammatical classes. Furthermore, compound words can be extracted by employing an automatic technical term extraction system [Nakagawa03] or the Japanese dependency parser CaboCha. In addition to plain text documents, the system is capable of extracting text from various file formats such as PDF, Microsoft Word, Excel, and PowerPoint.
Another crucial role of the input document selection module is to identify sentence boundaries within the input documents. Sentence boundary identification is essential when applying association rules, which is one of the methods used to support the construction of non-taxonomic relations in an ontology. The module automatically determines sentence boundaries based on the Japanese full stop (。), periods (.), and line breaks. However, if these markers are absent, the module may incorrectly identify sentence boundaries. Such misidentification leads to a decrease in the accuracy of relation construction using association rules. To address this issue, the module allows users to manually correct sentence boundaries.
Input Term Selection Module
In the input term selection module, the user selects input terms from the term set automatically extracted by the previous module. This selection process is performed while considering multiple factors, including compound words, parts of speech (POS), TF (Term Frequency), IDF (Inverse Document Frequency), TF-IDF scores, and superconcepts. Here, a superconcept refers to a concept positioned at a higher level within the conceptual hierarchy of the reference ontology. These superconcepts are pre-defined manually by the user. By referencing both a term and its corresponding superconcept simultaneously, the user can understand and categorize the automatically extracted terms at a more abstract level.
For instance, if the EDR Electronic Dictionary is used as the reference ontology and “Concrete Object” is set as a superconcept, any extracted term that matches a label of a hyponym (subordinate concept) of “Concrete Object” will be displayed with “Concrete Object” indicated as its superconcept.
If a necessary input term is not present in the input documents, or if the input document selection module fails to extract a term, the user can manually add input terms within this module. Furthermore, to prevent the omission of important terms, the system allows the user to verify the correspondence between the selected input terms and their specific occurrences within the input documents.
Input Concept Selection Module
In the input concept selection module, the user identifies the meaning of each input term by mapping it to a concept within the reference ontology selected in the ontology selection module. Since a single term may have multiple meanings, multiple concepts may share the same label as a given term. The module presents the input term alongside its candidate concepts to the user, who then selects the most appropriate concept for the target domain as the input concept.
For many compound words, a concept with an identical label does not exist in the reference ontology. To address this, the input concept selection module enables selection for a wider range of compound words through partial matching. There are two methods of concept mapping: exact matching and partial matching. Exact matching occurs when an input term perfectly matches a label in the reference ontology. Partial matching occurs when an input term only partially matches a label.
For input terms that do not result in an exact match, the system applies morphological analysis and attempts to map the term to the reference ontology while sequentially removing the leading morphemes. This approach is based on the assumption that in compound nouns, the word at the end (the head noun) is more significant than the preceding words (the modifiers) and represents the core meaning of the compound. This assumption follows the empirical rule that preceding words typically modify the final word in a compound noun. Therefore, the module performs partial matching so that the resulting match includes the suffix of the input term, ultimately mapping it to the concept corresponding to the longest matching term. For compound words identified through partial matching, the hierarchy is constructed by treating the term as either a hyponym (subordinate concept) or an alias (synonym) of the matched concept.
For example, consider the input term “rocket delivery system”. If “rocket delivery system” does not produce an exact match, it is decomposed into “rocket,” “delivery,” and “system” via morphological analysis. The system first attempts to match “delivery system”, and then “system”. In this case, if “delivery system” is not found but “system” exists in the reference ontology, the concept for “system” is presented as a candidate meaning. The user then decides whether to define “rocket delivery system” as a hyponym of the “system” concept or as an alias for it.
Input terms that do not match any concept in the reference ontology are categorized as unmatched terms. In the ontology refinement module, the user manually defines their hierarchical relationships at appropriate positions within the taxonomy. Furthermore, even if an input term matches a concept in the reference ontology, a semantically equivalent concept may not exist. In such cases, by selecting “unmatched terms” during selection, the term is categorized as an unmatched term. As with unmatched terms, the user manually defines the hierarchical position for these terms later.
Semi-automation of input concept selection
When the number of input terms is large or when terms are polysemous (possessing multiple meanings), the process of input concept selection imposes a significant burden on the user. The input concept selection module supports this process primarily through two types of automated concept selection methods. Both methods calculate an evaluation value for each candidate concept corresponding to an input term and rank them accordingly. By presenting these candidates to the user in descending order of their evaluation values, the module facilitates more efficient concept selection.
The first automated selection method calculates evaluation values for a target concept based on three specific metrics.
The maximum number of concepts that have labels matching the input term set (input vocabulary) along each path from the target concept to the root concept.
The number of hyponyms (subordinate concepts) of the target concept that have labels matching the input vocabulary.
The number of sibling concepts of the target concept that have labels matching the input vocabulary.
Users can select one or more of these metrics, and the candidate concepts are ranked based on the sum of the evaluation values obtained from the chosen metrics.
The second automated selection method first identifies the set of all candidate concepts for the input terms. Next, it determines all possible pairs within this concept set and calculates the conceptual distance for each pair. For a given concept, its evaluation value is defined as the sum of the reciprocals of the conceptual distances between it and all other concepts in the set. In cases where multiple inheritance exists, multiple methods for calculating conceptual distance are available; therefore, the user can choose to use the shortest distance, longest distance, or average distance.
To simplify selection via partial matching, the module allows the selection result for a specific partially matched term to be applied to all other terms that share the same partial match. For example, if “battery charging device,” “noise measuring device,” and “valve operation inspection device” are all partially matched to the term “device,” the selection result for “device” can be automatically applied as the input concept selection result for all three input terms.
Ontology Construction Modules
The ontology construction module is composed of two sub-modules: the hierarchy construction module and the relation construction module.
In the hierarchy construction module, an initial model of the conceptual hierarchy is built by referencing the taxonomic structure of the reference ontology. Meanwhile, the relation construction module identifies a set of concept pairs based on co-occurrence analysis, utilizing the input documents and the set of input concepts.
Together, the initial conceptual hierarchy and the set of concept pairs constitute the initial domain ontology. This initial ontology is subsequently refined through user interaction within the ontology refinement module.
The following sections provide detailed descriptions of the hierarchy construction and relation construction modules.
Hierarchy Construction Module
In the hierarchy construction module, an initial model of the conceptual hierarchy—serving as the foundation of the domain ontology—is constructed based on the taxonomic structure of the reference ontology.
The input module distinguishes between exactly-matched concepts (input concepts that perfectly match an input term) and partially-matched concepts (input concepts with only a partial match). Depending on this distinction, different hierarchy construction methods are applied. The following sections describe the respective hierarchy construction methodologies for both exactly-matched and partially-matched concepts.
Hierarchy Construction for Exactly-Matched Concepts
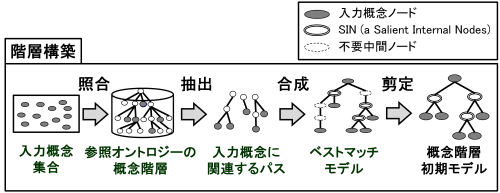
Fig. 6 Hierarchy Construction Process for Exactly-Matched Concepts
The process of hierarchy construction for exactly-matched concepts is illustrated in Fig. 6. In this process, the system extracts and integrates all paths from the reference ontology that lead from the exactly-matched concepts (treated as leaf nodes) to the root concept. The resulting conceptual hierarchy is referred to as the Best Match Model.
The Best Match Model in Fig. 6 consists of three types of nodes:
Input Concept Nodes (enclosed by a single line): Concepts in the reference ontology that correspond to user-selected input terms; these are indispensable for the domain ontology.
SIN (Salient Internal Nodes) (enclosed by double lines): Internal nodes identified as significant for the hierarchy.
Unnecessary Intermediate Nodes (enclosed by a dotted line): Nodes that do not contribute to the essential structure.
Nodes extracted from the reference ontology that are not input concept nodes are categorized as either SINs or unnecessary intermediate nodes.
A SIN is defined as a node that has one or more input concept nodes as its child nodes. SINs play a crucial role in preserving the topological relationships among input concepts—specifically, ancestral, parental, and sibling relationships. In contrast, unnecessary intermediate nodes are those that do not have any input concept nodes as children. Since these nodes do not contribute to maintaining the topological relationships between input concepts, the hierarchy construction module identifies them as redundant and removes them from the Best Match Model.
The process of removing unnecessary intermediate nodes is called pruning. The conceptual hierarchy resulting from pruning, which consists solely of input concept nodes and SINs, is termed the initial model of the conceptual hierarchy. This initial model is further refined through user interaction using conceptual hierarchy refinement methods, ultimately becoming the final conceptual hierarchy in the domain ontology.
Hierarchy Construction for Partially-Matched Concepts
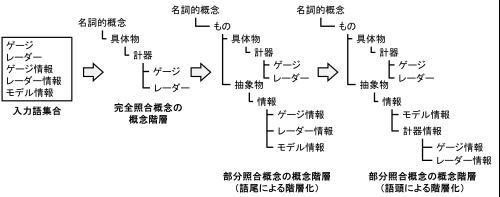
Fig. 7 Hierarchy Construction Process for Partially-Matched Concepts
n the hierarchy construction module, a stratification method based on prefixes and suffixes is applied to partially-matched concepts. Fig. 7 illustrates an example of this process. A partially-matched concept is a conceptualized input term that only partially matches a label in the reference ontology. As described in the input concept selection module, if an exact match is not found, the system performs morphological analysis and attempts a partial match that includes the suffix. In this context, the part of the label containing the suffix is defined as the suffix portion, and the preceding part is defined as the prefix portion. For instance, if the input term “gauge information” matches the concept “information”, “gauge” is the prefix portion and “information” is the suffix portion. During the input concept selection phase, the user chooses whether to treat the partially-matched term as an alias or a hyponym of the matched concept. The following explanation assumes the user has chosen to define it as a hyponym.
In the example shown in Fig. 7, the user initially selects “gauge,” “radar,” “gauge information,” “radar information,” and “model information” as input terms. Since “gauge” and “radar” have identical labels in the reference ontology, they are processed according to the hierarchy construction for exactly-matched concepts. Conversely, “gauge information,” “radar information,” and “model information” are partially matched to the “information” concept. In the suffix-based stratification, the system first constructs the hierarchy for the “information” concept following the exactly-matched process, then defines the three “information” terms as hyponyms of the “information” concept.
The prefix-based stratification focuses on the prefix portion of these partially-matched concepts. If a concept with the same label as the prefix portion already exists within the developing hierarchy, the system creates a new intermediate concept whose label combines the superconcept of that prefix and the label of the suffix-matched concept. Then, it redefines the hierarchy by placing the partially-matched concepts under this newly created intermediate concept. Since the prefix often serves to modify the suffix, combining prefix-based stratification with suffix-based methods allows for the construction of a more granular and detailed conceptual hierarchy.
As shown in Fig. 6, in the hierarchy built only through suffix-based stratification, the “gauge” and “radar” concepts (which correspond to the prefixes of “gauge information” and “radar information”) are defined as hyponyms of the “instrument” concept. By applying prefix-based stratification here, a new concept “instrument information” —combining “instrument” and “information”—is created and defined as the superconcept of “gauge information” and “radar information.” The introduction of this “instrument information” concept distinguishes these terms from “model information” and enables the systematic classification of information related to instruments.
Relationship Construction Module
To assist in defining other relations, the relationship construction module employs two co-occurrence-based methods - WordSpace and association rules - to extract candidate concept pairs for other relations from the input documents and input vocabulary.
Extraction of Concept Pairs via WordSpace
WordSpace [Hearst96] is employed as a method for computing co-occurrence statistics. WordSpace is a corpus-based approach that induces semantic representations of large word sets from the co-occurrence statistics of a vocabulary. Through WordSpace, each occurring term can be represented as a vector encoding co-occurrence information. The multidimensional vector space formed by this collection of word vectors constitutes the WordSpace, and the inner product between two vectors serves as a measure of contextual similarity between occurring terms. Based on the co-occurrence information obtained from WordSpace, contextually similar concept pairs are extracted from the input documents and utilized as candidate concept pairs potentially relevant to the definition of other relations. We assume that “similarity of context suggests the existence of some conceptual relationship between the terms.”
The following describes the procedure for extracting contextually similar concept pairs based on WordSpace ( Fig. 8 ).
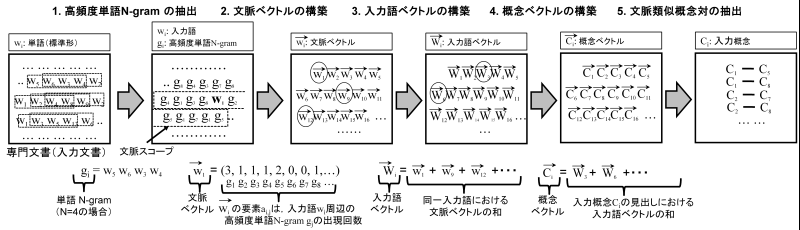
Fig. 8 Procedure for Extracting Contextually Similar Concept Pairs
1. Extraction of High-Frequency Word N-grams
Phrases composed of N words (word N-grams) are extracted from domain documents and used as the minimal unit of co-occurrence. Compared to computing N-gram statistics at the character level, this approach allows co-occurrence information for meaningless character sequences to be excluded, enabling the extraction of information more useful for representing the context of domain documents. The extracted phrases are converted to their canonical forms, and duplicates are eliminated by consolidating identical forms. From the resulting set of word N-grams, those with high occurrence frequency in the domain documents (high-frequency word N-grams) are selected for use in constructing the WordSpace. This allows the input documents to be treated as sequences of high-frequency word N-grams. In the relationship construction module, users can configure both the word count N and the minimum occurrence count when extracting high-frequency word N-grams.
Note
While [Hearst96] constructs WordSpace using character-level co-occurrences, the relationship construction module treats word-level N-gram co-occurrences as the minimal unit. Consequently, the 4-gram vector construction step - performed in standard WordSpace construction to represent character-level co-occurrences in a consolidated form - is omitted.
2. Construction of Context Vectors
Next, context vectors are constructed in order to compare the contexts of two given input terms. A context vector represents, as a vector, the occurrence counts of high-frequency word N-grams in the vicinity of a given input term. The element \(a_{i,j}\) of context vector \(\overrightarrow{w_i}\) is the occurrence count of high-frequency word N-gram \(g_j\) within the surrounding region of the occurrences of input term \(w_i\) (the context scope). In the relationship construction module, users can configure the context scope by specifying the number of words before and after input term \(w_i\) within which high-frequency word N-grams are included in the construction of the context vector.
3. Construction of Input Term Vectors
Next, the input term vector is derived from the context vectors as a vector representation of each input term. The input term vector \(\overrightarrow{W_i}\) is represented by the sum of the context vectors \(\overrightarrow{w_i}\) across all occurrences of input term \(w_i\) in the domain documents.
4. Construction of Concept Vectors
Next, concept vectors are derived from the input term vectors as vector representations of the input concepts. The input concept selection module has already identified the concepts in the reference ontology that correspond to the input terms (input concepts). The concept vector is obtained as the sum of the input term vectors over the headwords (input terms) of the input concept. The concept vector \(\overrightarrow{C}\) is expressed by (1). \(\mathcal{A}(w)\) denotes the set of all occurrences of input term \(w\) in the domain documents. \(\overrightarrow{w}(i)\) denotes the context vector at position \(i\) of input term \(w\) in the domain documents. \(synset(C)\) denotes the set of headwords of concept \(C\).
5. Extraction of Contextually Similar Concept Pairs
Through the processing described above, concept vectors can be obtained for all input concepts. The inner product between concept vectors yields the contextual similarity between concepts. In the relationship construction module, users can set a threshold value against which contextual similarity is measured. Concept pairs whose contextual similarity exceeds the user-specified threshold are extracted as contextually similar concept pairs.
The contextual similarity \(sim(\overrightarrow{C_1}, \overrightarrow{C_2})\) between concept vectors \(\overrightarrow{C_1}\) and \(\overrightarrow{C_2}\) is computed using (2).
Since no concept relation has yet been inferred to explicitly characterise the relationship between concepts, the concept relation non-TAXONOMY is assigned as the initial value prior to inference. The extracted contextually similar concept pairs may include hierarchical relationships. Accordingly, any hierarchical relationships already defined in the concept hierarchy are excluded from the set of contextually similar concept pairs.
Extraction of Concept Pairs via Association Rules
Association rules are employed as a second method for extracting candidate concept pairs for the definition of other relations from domain documents. Correlation denotes a co-occurrence property whereby the occurrence of one event tends to be accompanied by the occurrence of another. Furthermore, an association rule of the form \(A \Rightarrow B\) signifies that the occurrence of event \(A\) tends to be followed by the occurrence of event \(B\). The extraction of association rules is one of the representative data mining techniques and has also been applied to the definition of other relations [Agrawal94]. Here, combinations of input terms co-occurring within a single sentence in the input documents are extracted as association rules and utilised as candidate concept pairs for the definition of other relations. It is assumed that some conceptual relationship exists between the concepts included in the extracted association rules.
The following describes the definition of association rules and the Apriori algorithm for association rule extraction. The explanations of association rules and the Apriori algorithm are based on Section 2.5 of Fundamentals of Data Mining [Motoda06].
Definition of Association Rules
Association rules are extracted from the transaction set \(T\) shown in (3). A transaction \(t_i\) represents the unit of data grouping in a database. Here, since a single sentence in the input documents is taken as the unit of data grouping, the number of elements \(n\) in the transaction set corresponds to the number of sentences contained in the input documents.
Each element \(t_i\) of \(T\) is an item set. Here, items are taken to be input terms. That is, \(t_i\) is represented as the set of input terms contained in the \(i\)-th sentence of the input documents. \(t_i\) is expressed by (4). The \(C\) in (4) denotes the set of all input terms contained in the input documents.
For item sets \(X_k\) and \(Y_k\) each containing \(k\) items, an association rule is expressed as \(X_k \Rightarrow Y_k (X_k, Y_k \subset C, X_k \cap Y_k = \emptyset)\). Here, \(X_k\) is referred to as the antecedent and \(Y_k\) as the consequent. Both the antecedent and the consequent may contain multiple items.
Two metrics for measuring the significance of association rules are support and confidence. Support denotes the proportion of all transactions in which a given association rule appears. The support \(support(X_k \Rightarrow Y_k)\) of \(X_k \Rightarrow Y_k\) is defined as the proportion of transactions containing both \(X_k\) and \(Y_k\) in \(T\), as expressed by (5).
Confidence denotes the proportion of cases in which the consequent occurs given that the antecedent has occurred. The confidence \(confidence(X_k \Rightarrow Y_k)\) of \(X_k \Rightarrow Y_k\) is defined as the proportion of transactions containing \(X_k\) in \(T\) in which \(Y_k\) also appears, as expressed by (6).
In association rule extraction, unless threshold values are imposed on both support and confidence, a combinatorial explosion occurs and a large number of meaningless rules are generated. Therefore, thresholds are set for both support and confidence in association rule extraction, and only association rules whose support and confidence meet or exceed these values are extracted. These respective thresholds are referred to as minimum support and minimum confidence. Furthermore, item sets whose support meets or exceeds the user-specified minimum support are referred to as frequent item sets.
Although association rules generally permit multiple items in the antecedent, since the goal here is to extract concept pairs, a single item is admitted in both the antecedent and the consequent - that is, pairs of input terms are extracted. As with the extraction of concept pairs using WordSpace, since no concept relation has yet been inferred to explicitly characterise the relationship between concepts, the concept relation non-TAXONOMY is assigned as the initial value.
Apriori Algorithm for Association Rule Extraction
Association rules are extracted through the following two steps.
Step 1: Acquire frequent itemsets.
Step 2: Derive association rules with confidence greater than or equal to the minimum confidence from \(F\).
Step 2 is the process of deriving rules from \(F\) obtained in Step 1, and its computational load is relatively small. Step 1, on the other hand, carries a heavy load because it repeatedly scans \(T\) and examines the support of numerous itemsets. For this reason, it has long been considered that developing an efficient algorithm for Step 1 is the key to a practical association rule mining algorithm. The first method to address this challenge was the Apriori algorithm [Agrawal94], proposed by Rakesh Agrawal et al. at the IBM Almaden Research Center. The Apriori algorithm is currently the most widely used association rule mining algorithm, and is also employed in this study for the implementation of the relationship construction module.
The Apriori algorithm is described below.
The Apriori algorithm exploits the anti-monotonicity property of itemset support: “if \(A\) is a frequent itemset, then all of its subsets are also frequent itemsets,” and conversely, its contrapositive: “if \(B\) is not a frequent itemset, then any itemset \(A\) that contains \(B\) is also not a frequent itemset.” By leveraging these properties, the algorithm can efficiently perform pruning to discover frequent itemsets. For example, if {1, 2} is not a frequent itemset, then no itemset containing {1, 2} (such as {1, 2, 3}) can be a frequent itemset either, and therefore its support does not need to be examined.
In the Apriori algorithm, support is computed starting from itemsets with fewer elements. When the support of a given itemset falls below the minimum support threshold, the anti-monotonicity property is applied to prune all itemsets that contain it — that is, they are excluded from consideration as frequent itemset candidates.
Let \(F_k\) denote the set of frequent itemsets of size \(k\), and \(C_k\) denote the set of candidate frequent itemsets of size \(k\). The procedural steps of the Apriori algorithm are as follows.
Generate \(C_{k+1}\) from \(F_k\). For each element of \(C_{k+1}\), check whether every subset of size \(k\) is contained in \(F_k\); if not, remove that element from \(C_{k+1}\).
Scan \(T\) to compute the support of each element in \(C_{k+1}\).
Extract \(F_{k+1}\) from \(C_{k+1}\) by retaining only those elements whose support meets the minimum support threshold.
Repeat steps (1) through (3) until no new frequent itemsets are found.
Fig. 9 shows an example of frequent itemset extraction using the Apriori algorithm with a minimum support of 0.50 (2/4 = 0.50). In Fig. 9, since \(T\) contains four transactions, any itemset appearing two or more times in \(T\) qualifies as a frequent itemset. First, the occurrences of all size-1 itemsets in the transactions of \(T\) are counted to construct \(C_1\). Itemsets in \(C_1\) that meet or exceed the minimum support threshold are extracted to obtain \(F_1\). Next, \(C_2\) is generated from \(F_1\). At this stage, no elements are pruned from \(C_2\), because every size-1 subset of each element in \(C_2\) is already a frequent itemset. \(T\) is then scanned to derive \(F_2\) from \(C_2\). Next, \(C_3\) is generated from \(F_2\). At this point, itemsets such as {1, 2, 3} and {1, 3, 5} are initially extracted as candidates for \(C_3\). However, their respective subsets {1, 2} and {1, 5} are not frequent itemsets; consequently, {1, 2, 3} and {1, 3, 5} cannot be frequent itemsets either, and are pruned from \(C_3\). As a result, \(C_3\) contains only {2, 3, 5}. Scanning \(T\) reveals that {2, 3, 5} occurs twice, giving it a support of 0.50, which meets the threshold. Therefore, \(F_3\) = {2, 3, 5}. Since no \(C_4\) can be generated from {2, 3, 5}, the algorithm terminates here.
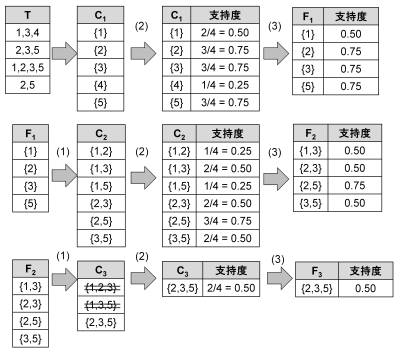
Fig. 9 An Example of Frequent Itemset Extraction Using the Apriori Algorithm
Construction of Property Hierarchies and Definition of Other Relations Using the EDR Concept Description Dictionary
The ontology construction module is capable of constructing property hierarchies and defining other relations using the EDR Concept Description Dictionary. The EDR Concept Description Dictionary defines eight types of conceptual relationships, centred on case relationships in which verbal concepts govern nominal concepts: agent, object, goal, implement, a-object, place, scene, and cause. The ontology construction module treats verbal concepts defined in the EDR Concept Description Dictionary and their subordinate concepts as OWL object properties, and constructs the property hierarchy separately from the nominal concept hierarchy (class hierarchy) during hierarchy construction.
Furthermore, among the eight types of conceptual relationships, the ontology construction module defines nominal concepts bearing an agent relationship as the domain of a property, and nominal concepts bearing an object relationship as the range of a property.
The same algorithm applied to exact-match and partial-match concept hierarchisation in class hierarchy construction is also applicable to property hierarchy construction. When hierarchising exact-match concepts, unnecessary concepts are pruned. This gives rise to the following cases in which either the consistency of other relation definitions cannot be maintained, or other relation definitions are lost entirely:
A pruned concept in the class hierarchy is defined as the value of an agent or object relationship.
An agent or object relationship is defined for a pruned concept in the property hierarchy.
In the ontology construction module, case 1 is addressed by substituting the value of the agent or object relationship with a subordinate concept of the pruned concept, thereby preserving consistency. Case 2 is addressed by having the domain and range inherited by the subordinate concepts of the pruned property, thereby preventing the loss of other relation definitions.
Ontology Refinement Module
The ontology refinement module consists of the hierarchy refinement module and the relationship refinement module. In the ontology refinement module, ontology refinement is carried out through interaction with the user, based on the initial concept hierarchy model constructed by the ontology construction module and the concept pair set for the definition of additional relationships.
The following describes the hierarchy refinement module and the relationship refinement module.
Hierarchy Refinement Module
Since the initial concept hierarchy semi-automatically constructed from a reference ontology (in particular, a general ontology) defines general hierarchical relationships, the user must adjust the initial concept hierarchy to a specific domain while taking into account a problem known as concept drift - the semantic shift of concepts resulting from changes in the target domain. To manage concept drift, the hierarchy refinement module applies three strategies: Strategy 1: Matching Result Analysis, Strategy 2: Pruning Result Analysis, and Strategy 3: Multiple Inheritance Elimination. Fig. 10 illustrates the concept hierarchy refinement process. Strategy 1 identifies concept drift from the perspective of matching results between the input concept set and the general-purpose ontology, Strategy 2 from the perspective of pruning results, and Strategy 3 from the perspective of multiple inheritance. The following describes each strategy in detail.
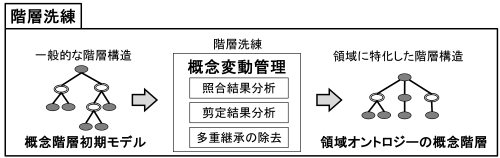
Fig. 10 Concept Hierarchy Refinement Process
Strategy1: Matched result analysis
In Strategy 1, the initial concept hierarchy model is partitioned into regions that are reusable and regions that are not reusable (i.e., regions in which concept drift is estimated to have occurred) based on the positional relationships of input concepts, and concept drift is resolved by relocating the non-reusable regions. Here, relocation refers to redefining the concepts contained in a non-reusable region as subordinate concepts of another appropriate concept.
Since input concepts (best-match nodes) are considered largely valid from the perspective of the target domain, paths along which they appear consecutively can be regarded as concentrating valid concepts and are thus treated as reusable paths. Such paths are referred to as PAB (PAths including only Bestmatches). Conversely, regions containing SINs are considered candidates for relocation, as they may exhibit differences in concept structure (concept drift). Such regions are referred to as STM (SubTrees manually Moved). The definitions of PAB and STM are given below.
- Definition of PAB
A path along which multiple input concepts (best-match nodes) appear consecutively from the root concept.
- Definition of STM
A subtree rooted at a SIN, all of whose child nodes consist exclusively of best-match nodes.
Fig. 11 shows examples of PAB and STM. Subtrees enclosed by solid lines represent PABs, and subtrees enclosed by dashed lines represent STMs. Users refine the initial concept hierarchy model by relocating STMs, thereby constructing the domain concept hierarchy. The destination of each STM relocation is determined by the user; if the user judges that relocation is unnecessary, the STM is left in place. The root node of an STM that the user deems unnecessary during relocation may be deleted. Since Strategy 1 is derived by analysing matching results, it is referred to as Matched Result Analysis (MRA).
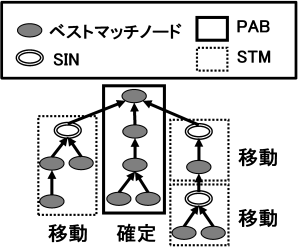
Fig. 11 Strategy1: Matched result analysis
Strategy2: Trimmed result analysis
In Strategy 2, when there is a large discrepancy in the number of intermediate concepts removed during pruning between sibling nodes sharing the same parent node (superordinate concept) in the initial concept hierarchy model, the strategy suggests that the hierarchical relationships be restructured.
When all regions containing intermediate concepts deleted during the pruning process — along with concepts other than best-match nodes connected to them — are removed, this indicates that the method of concept differentiation in the reference ontology differs from that of the target domain. Users are prompted to restructure the differentiation of such subtrees. Restructuring is suggested to the user for parent-child node pairs in which the discrepancy in the number of deletions during pruning is at least one-third of the distance from the root concept to the terminal concepts in the initial concept hierarchy model. The number of deletions during pruning from the root concept to the terminal concepts can also be set arbitrarily by the user. Since Strategy 2 is carried out through analysis of pruning results of related information, it is referred to as Trimmed Result Analysis (TRA).
An example application of Trimmed Result Analysis is shown in Fig. 12. As a result of pruning the best-match model in Fig. 12, the entire region between concept A and concept D was removed. Such a change indicates that the classificatory attributes of concept A may be utilised for differentiation in a different form in the target domain, suggesting that concept drift has occurred at this point. In this example, in the target domain, concept D is restructured in the concept hierarchy not as a subordinate concept of concept A, but as a subordinate concept of concept C.
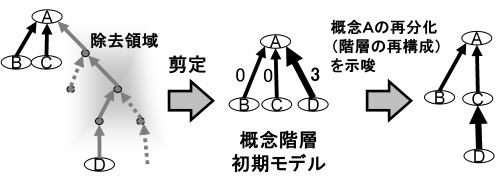
Fig. 12 Strategy2: Trimmed result analysis
Strategy3: Removing multiple inheritance
General ontologies such as WordNet and the EDR Electronic Dictionary make extensive use of multiple inheritance in order to define hierarchical relationships exhaustively. Multiple inheritance relationships in general-purpose ontologies are defined with various contexts taken into consideration. Consequently, the majority of inheritance relationships become unnecessary in any specific domain. The hierarchy refinement module facilitates the elimination of multiple inheritance by presenting the user with a list of concepts with multiple inheritance and indicating which concepts are held as superordinate concepts.
An example of multiple inheritance elimination is shown in Fig. 13. In Fig. 13, concept D inherits multiply from three concepts in the general ontology — concept A, concept B, and concept C — as its superordinate concepts. Here, concept A and concept C are deemed unnecessary as superordinate concepts, and the user removes the corresponding inheritance relationships.

Fig. 13 Strategy3: Removing multiple inheritance
Relationship Refinement Module
The relationship refinement module supports the user in defining relationships between concepts from the concept pair sets extracted by the relationship construction module via WordSpace and association rules. The relationship refinement module enables adjustment of parameters for WordSpace and association rules, merging of results, selection of correct or unnecessary concept pairs, and definition of relationships between concept pairs.
Visualization Module
To provide visual support for refining semi-automatically constructed domain ontologies, DODDLE-OWL integrates a Visualization Module. Specifically, DODDLE-OWL employs MR3 (Meta-Model Management based on RDFs Revision Reflection) [Morita06] for this purpose. MR3 is a graphical RDF/RDFS editor designed to manage relationships between RDF and RDFS descriptions. Using a dedicated plug-in, DODDLE-OWL can seamlessly interchange OWL ontologies with the MR3 environment.
The Visualization Module serves two primary roles in supporting domain ontology construction:
Concept Drift Management in the Refinement Module: The module visualizes the initial concept hierarchy generated by the Construction Module. This allows users to visually inspect and refine “concept drift” candidates suggested by the Refinement Module, facilitating more intuitive decision-making.
Externalization of the Domain Ontology: This refers to the comprehensive visualization of both taxonomic and non-taxonomic (other) relationships within the domain ontology. Since these relationships are constructed separately—in the Hierarchy Construction Module and the Relationship Construction Module, respectively—externalization is crucial. It enables users to refine the ontology while ensuring a structural balance between the taxonomic backbone and the associated properties.
Translation Module
A domain ontology constructed by DODDLE-OWL consists of hierarchical relations and non-taxonomic (other) relations.
The is-a hierarchy of classes is defined using the owl:Class class and the rdfs:subClassOf property.
The has-a hierarchy of classes (part-whole relations) is defined using the owl:Class class and the doddle:partOf property.
For properties, the is-a hierarchy is defined via owl:ObjectProperty and rdfs:subPropertyOf, while the has-a hierarchy uses owl:ObjectProperty and doddle:partOf.
Other relations are expressed as properties in OWL, where the domain and range of the property are set to the respective concept pair using the owl:ObjectProperty class, the rdfs:domain property, and the rdfs:range property.
The upper part of Fig. 14 illustrates the conversion to OWL format for a conceptual relationship where “aim” and “behavior” are defined as subclasses of the “act” class. The lower part of Fig. 14 shows the conversion process for an “other relation,” specifically where an “attribute” property defines the relationship between the “time” class and the “offer” class.
Furthermore, DODDLE-OWL defines the label of a concept using the rdfs:label property and the description using rdfs:comment. The preferred label for display is defined using the skos:prefLabel property. The preferred label refers to the specific label prioritized for display within the conceptual hierarchy when multiple labels are defined for a single concept.
Note
owl is a prefix of http://www.w3.org/2002/07/owl#. rdfs is a prefix of http://www.w3.org/2000/01/rdf-schema#.
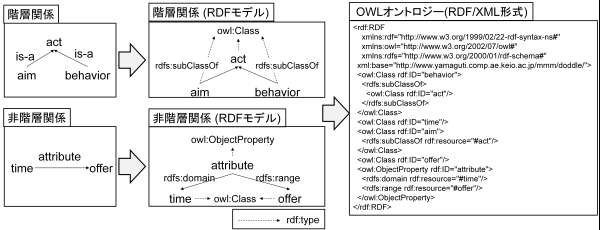
Fig. 14 Example of Converting a Domain Ontology to OWL Format via the Translation Module